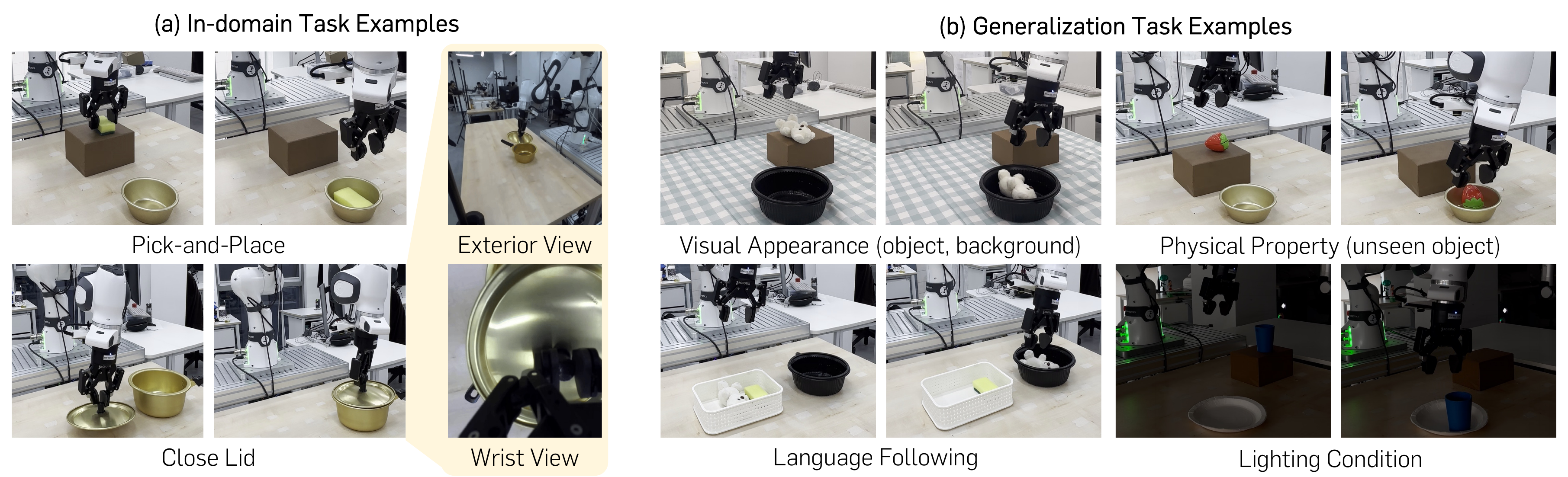
Motivation: VLM representations miss robotic signals
We visualize VLM embeddings of robot episodes performing the same task ("Open the microwave / cabinet door") across different scenes. Pre-trained VLM representations are dominated by visual appearance (e.g., scene layout, surrounding objects), clustering by visual cues rather than control-relevant factors. RS-CL instead guides embeddings to align with the robot's proprioceptive states, capturing common robotic signals (e.g., current pose, next action) and aligning all episodes by task progress.

Identical task trajectories
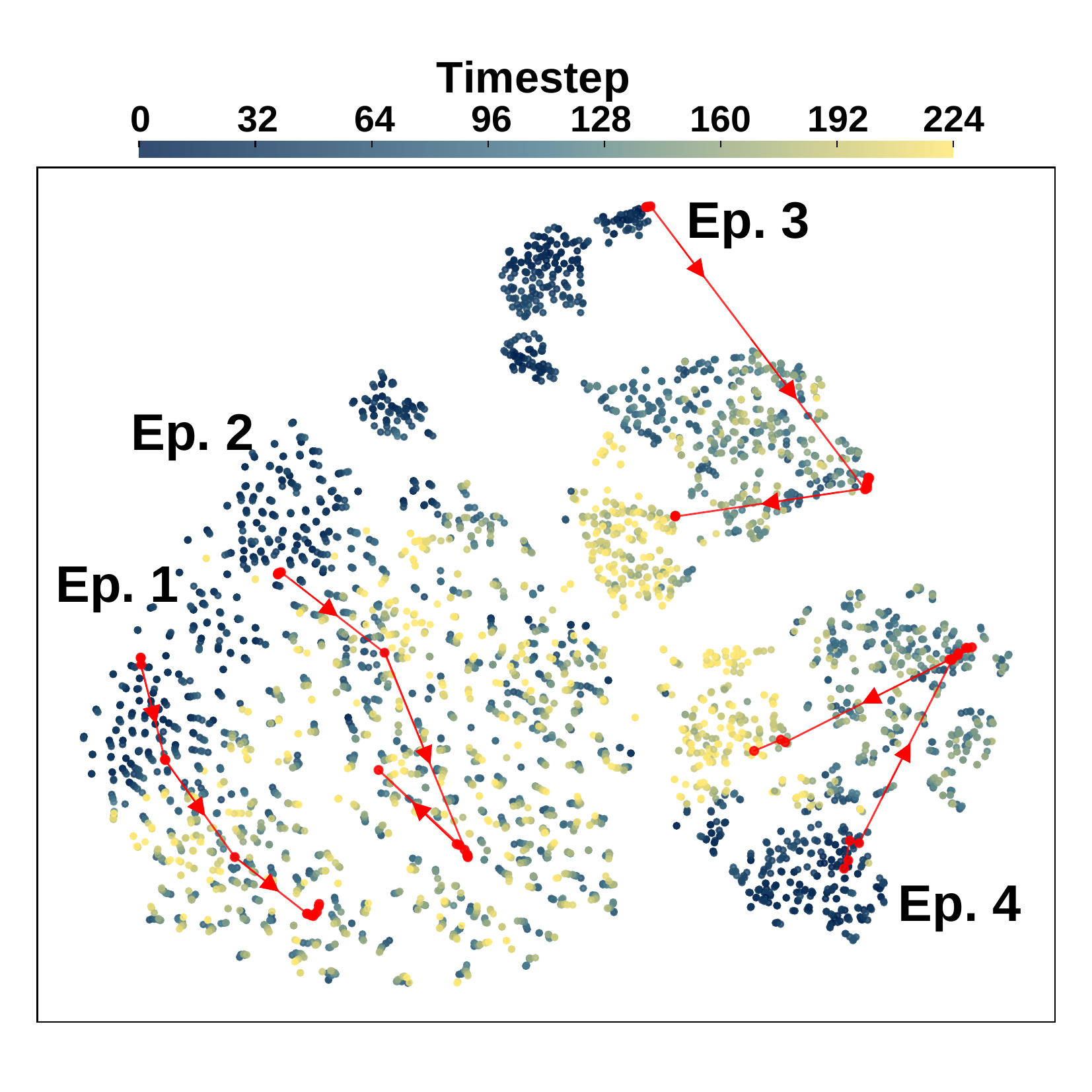
Pre-trained VLM representations
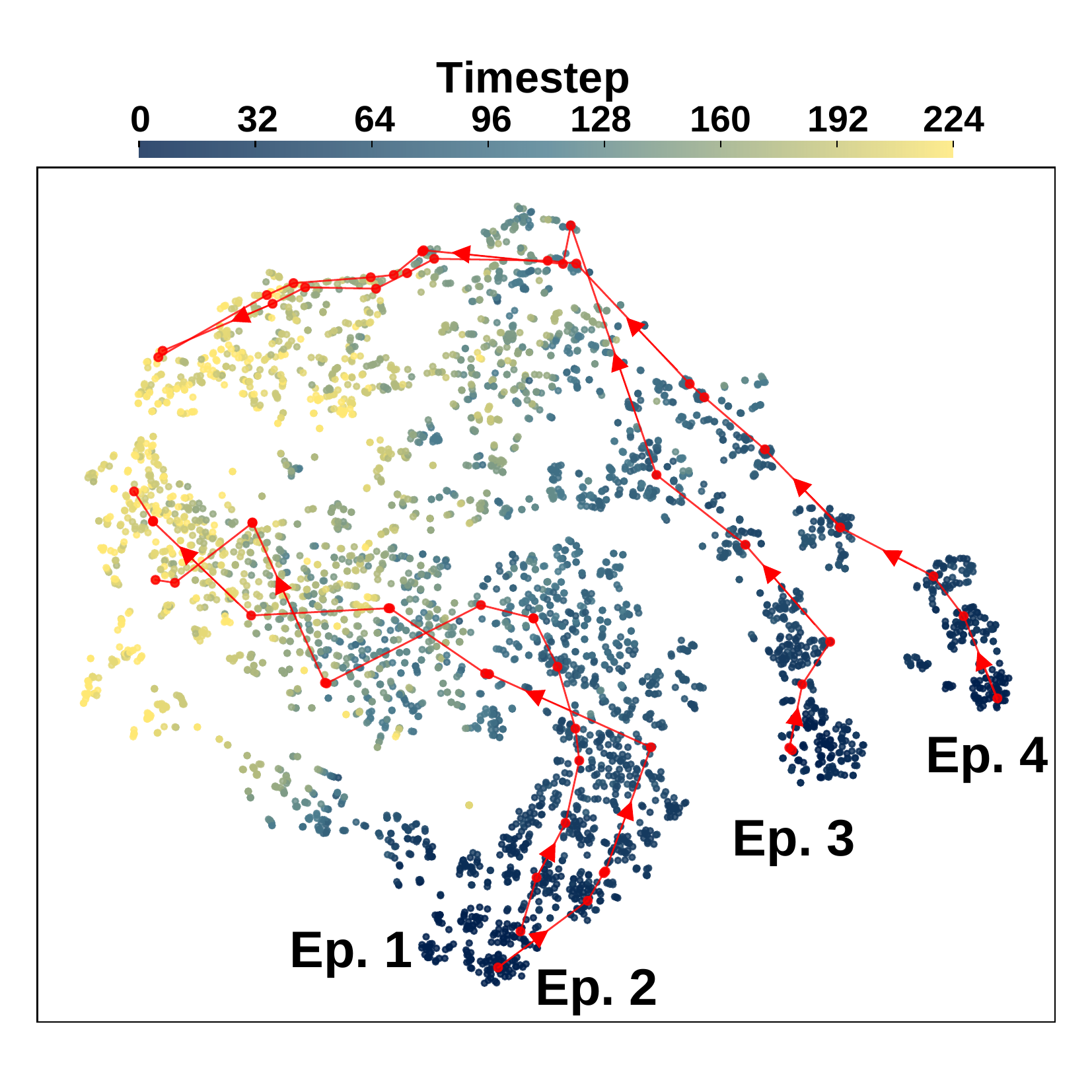
RS-CL aligned representations
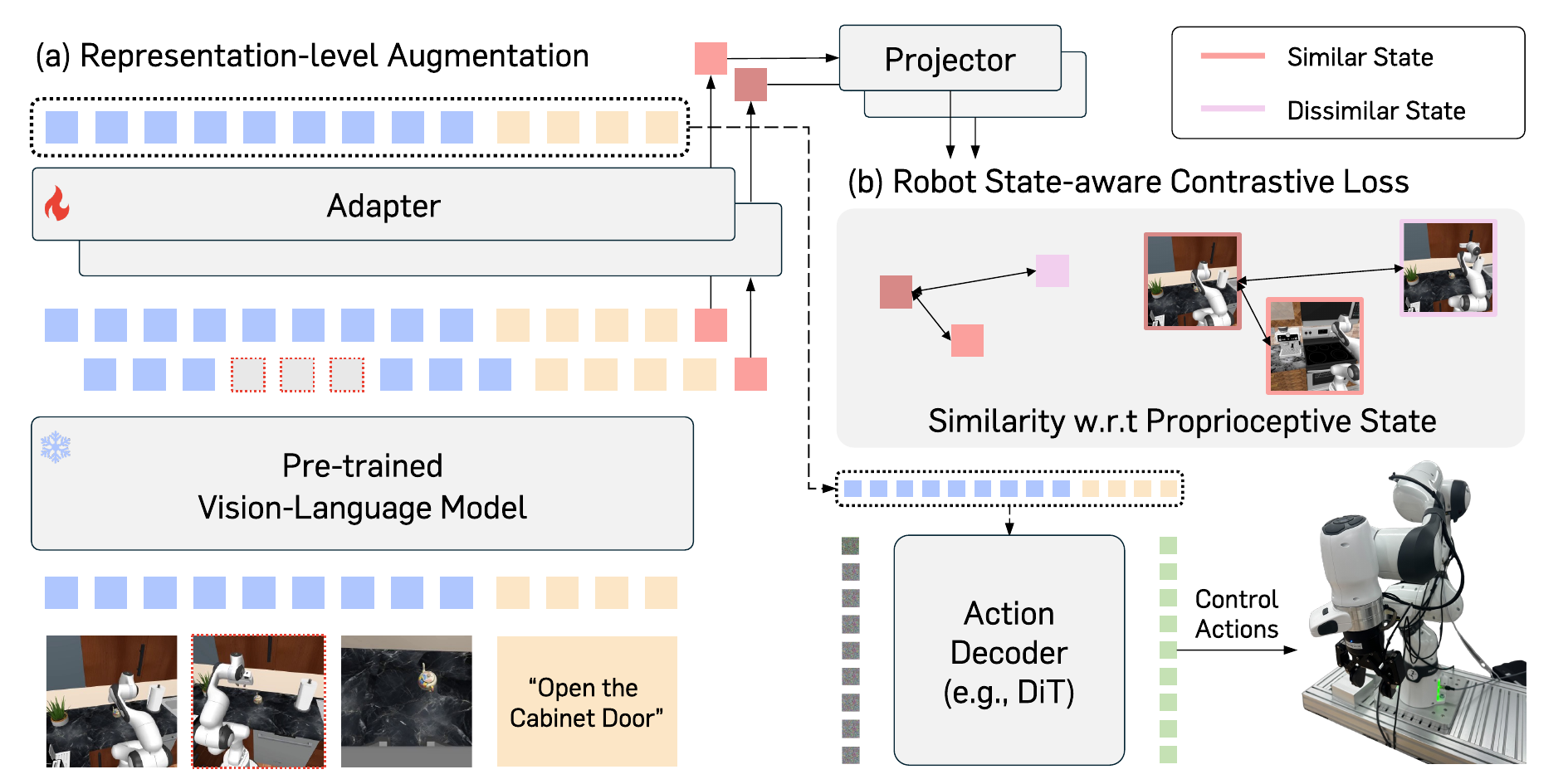
Method
Robot State-aware Contrastive Loss (RS-CL) is an objective that regularizes the VLM representation space using supervision from the robot's proprioceptive states. It is built from three key components:
- Learnable summarization token — amortizes long VLM output embeddings into a compact representation for efficient contrastive learning.
- Robot state-aware weighting — a soft-weighted InfoNCE loss that assigns pairwise weights from the relative distances between proprioceptive states, pulling together embeddings with similar robot states.
- View cutoff augmentation — a lightweight representation-level augmentation that masks out the feature slice of a randomly selected observation view, generating diverse contrastive pairs with minimal overhead.
By operating at the representation level and training end-to-end in a single stage, RS-CL remains fully compatible with existing VLA training pipelines.
Results
Representation analysis
RS-CL successfully injects control-relevant structure into the VLM representation while preserving the initial semantics.
| Representation | Scene Acc. (%) | Task-progress Acc. (%) |
|---|---|---|
| Pre-trained VLM embeddings | 99.6 | 1.2 |
| Embeddings trained with RS-CL | 93.6 | 22.9 |
| Ground-truth proprioceptive states | 53.1 | 25.6 |
KNN classification accuracy (%) on the representation space.
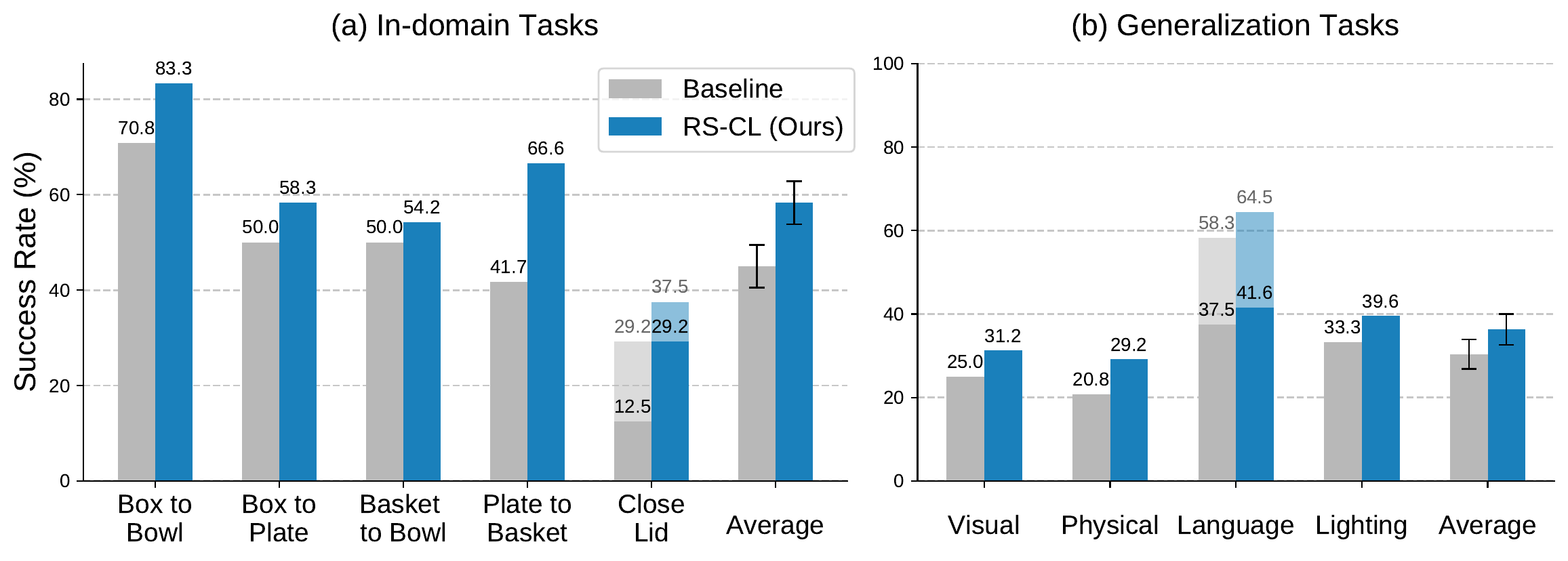
Real-robot manipulation
RS-CL raises manipulation precision on real robot tasks — improving average success rates from 45.0% to 58.3% — without harming generalization (e.g., visual appearance, physical properties, language following, lighting conditions).